

应用领域
APPLICATON
应用领域
电动时代的声学革命:深度解读西门子AVAS如何重塑安全与品牌声景——从法规合规到城市声态,揭秘电动车“声音身份证”的设计哲学,低速提示音/通过噪声
引言:当寂静成为危险,电动车需要怎样的“声音身份证”?
清晨的街道上,一辆电动车悄然滑过,行人浑然不觉——这不是科幻场景,而是混合动力与电动车(HEV/EV)普及后真实的安全隐患。传统燃油车的引擎轰鸣曾是城市声景的“背景音”,但电动化的寂静却让视障群体、儿童甚至普通行人暴露在风险中。
数据警示:美国国家公路交通安全管理局(NHTSA)研究显示,电动车在低速(<30 km/h)时与行人碰撞概率比燃油车高37%。这一现实催生了全球强制性法规——声学车辆警报系统(AVAS)。然而,AVAS不仅是“合规工具”,更是一场技术、艺术与商业的跨界实验:车企如何在警示音中嵌入品牌DNA?声学工程师如何平衡安全与城市噪声污染?仿真技术又如何颠覆传统开发流程?
第一部分 法规驱动:全球AVAS合规地图与安全逻辑
1.1 低速静音的致命隐患:为什么30 km/h是分水岭?
- 物理真相:轮胎与风噪的声压级(SPL)与车速呈指数关系。当车速超过30 km/h时,风噪(约60 dB)足以被行人感知;而低于此速度时,电动车声压级可能不足45 dB(相当于图书馆环境),难以被察觉。
- 人群风险:视障群体依赖听觉判断车辆位置与动态,儿童和低头族则因注意力分散成为高危人群。
1.2 全球法规“军备竞赛”:从欧盟R138到美国FMVSS 141
- 欧盟UNECE R138(2019生效):
- 测试场景:10/20 km/h匀速、6 km/h倒车。
- 频段要求:至少两个1/3倍频程带(含<1,600 Hz)达标。
- 动态行为:音调需随车速升高,以区分加速/减速。
- 美国FMVSS 141(2020生效):
- 扩展场景:新增30 km/h测试,覆盖更广速域。
- 频段组合:需满足非相邻频段叠加,增强声音辨识度。
- 中国GB/T 37153-2018:类似欧盟标准,但强调“声音不可关闭”。
车企合规成本:单一车型的AVAS开发与测试费用可达50万美元,且需适应多国法规差异。
第二部分 技术核心:从声学设计到传播优化的全链路突破
2.1 声音设计:在法规框架中寻找品牌“声纹”
- 阶次合成(Order Synthesis)的局限:
通过模拟内燃机阶次(如点火频率的谐波)生成声音,虽易被用户接受,但违背电动车“科技感”定位,且无法满足AVAS创新需求。 - 颗粒合成(Granular Synthesis)的崛起:
- 原理:将音频切割为毫秒级“颗粒”,随机重组并动态调整音高/时长,生成非重复性宽带声(图1)。
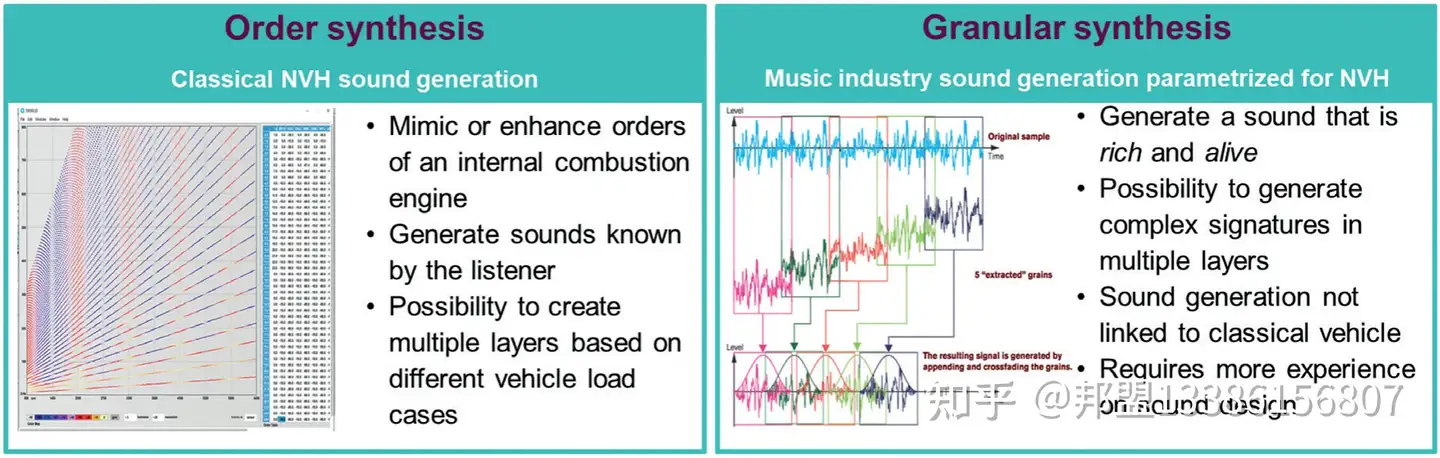
- 案例:宝马i系列采用类似合成器的“太空音效”,通过颗粒合成实现未来感警示音。
- 品牌声学战略:
- 豪华车:低频丰富(如雷克萨斯混动车型的“深海脉动”)。
- 运动车型:高频瞬态突出(如保时捷Taycan的“电子引擎咆哮”)。
2.2 传播优化:波束成形与声学隐身的博弈
- 被动定向性:扬声器布局的物理限制
- 传统方案:前/后保险杠单扬声器,声场呈半球形扩散,效率低且干扰环境。
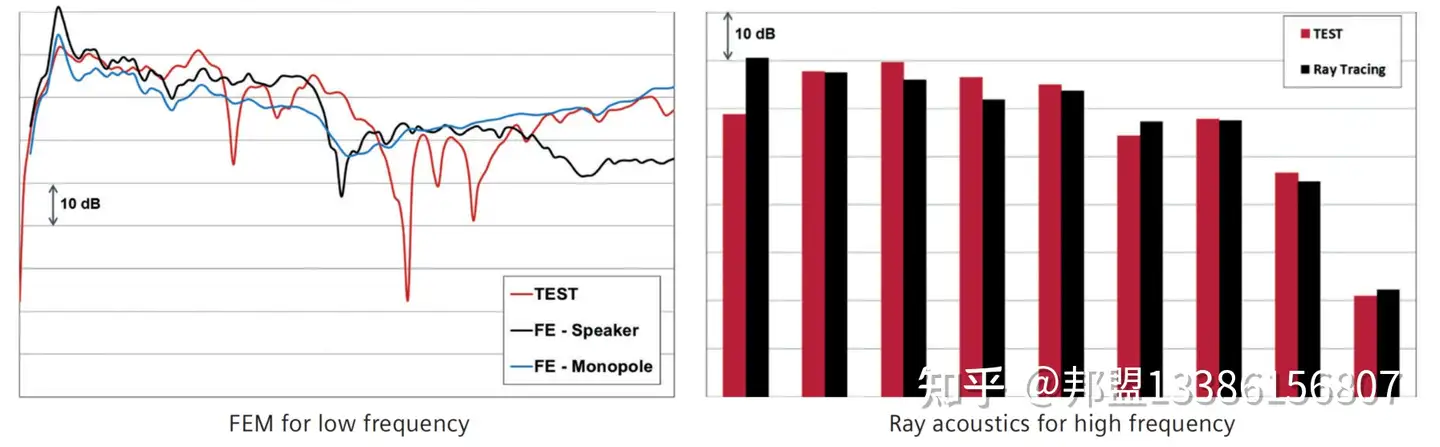
- 西门子仿真优化:通过FEM(有限元法)模拟不同位置声场,找到最优辐射效率点(图2)。
- 主动波束成形(Beamforming):
- 原理:利用扬声器阵列+时延控制,将声能聚焦于特定方向(图3)。
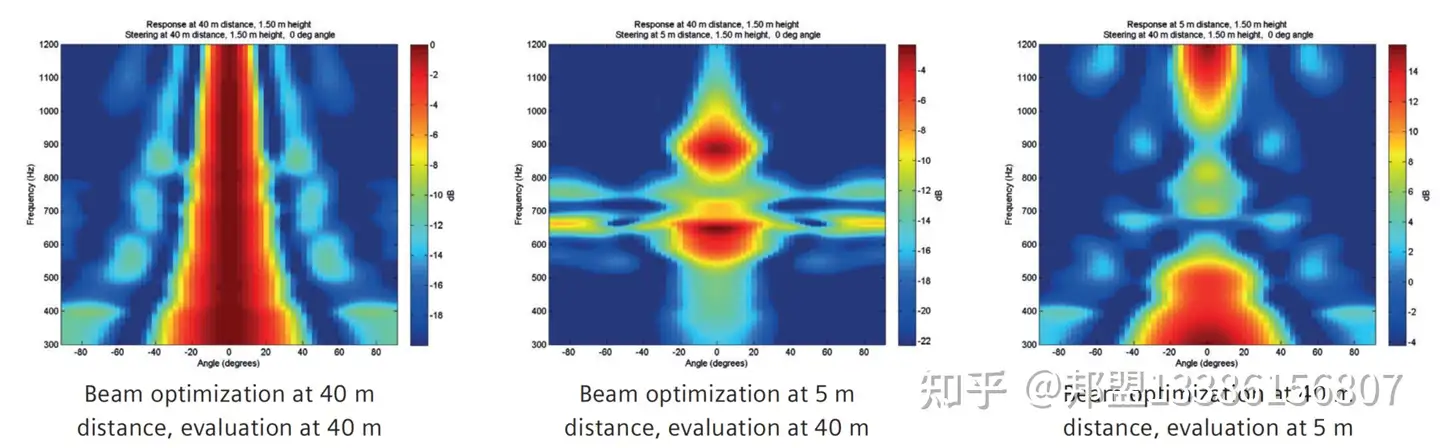
- 挑战:高频声波波长短(如1 kHz波长约34 cm),需密集阵列(间距<λ/2)才能有效控制。
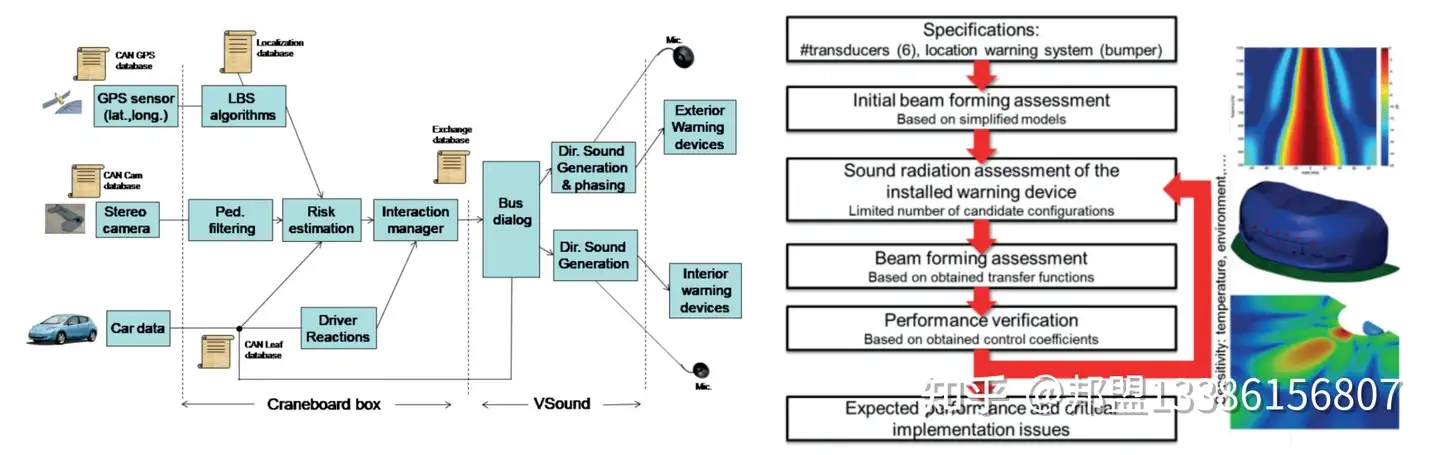
- 动态适应:结合摄像头检测行人位置,实时调整波束指向(图4)。
2.3 环境交互:城市声景的“消音器”与“放大器”
- 遮挡效应:车辆、建筑对声波的反射/吸收(图5)。
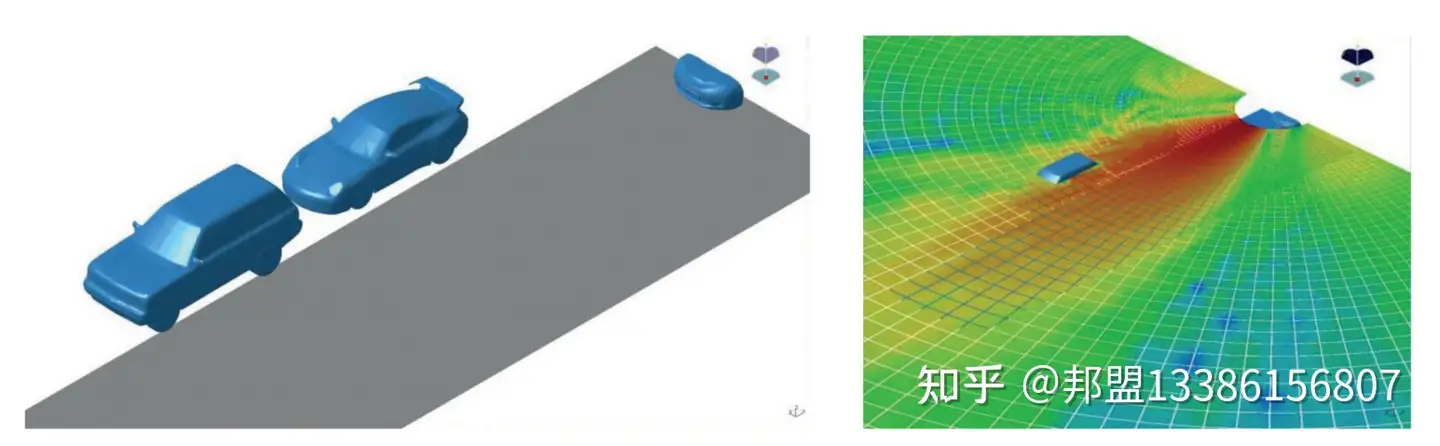
- BEM(边界元法)仿真:模拟多车并行场景,预测声场盲区。
- 地面阻抗:沥青、草地等不同材质对低频的吸收差异可达10 dB。
第三部分 仿真革命:虚拟声学如何缩短开发周期70%?
3.1 从物理原型到数字孪生:西门子Simcenter工具链
- Simcenter Sound Designer:
- 合规预检:输入扬声器-行人传递函数,提前预测法规达标情况(图6)。
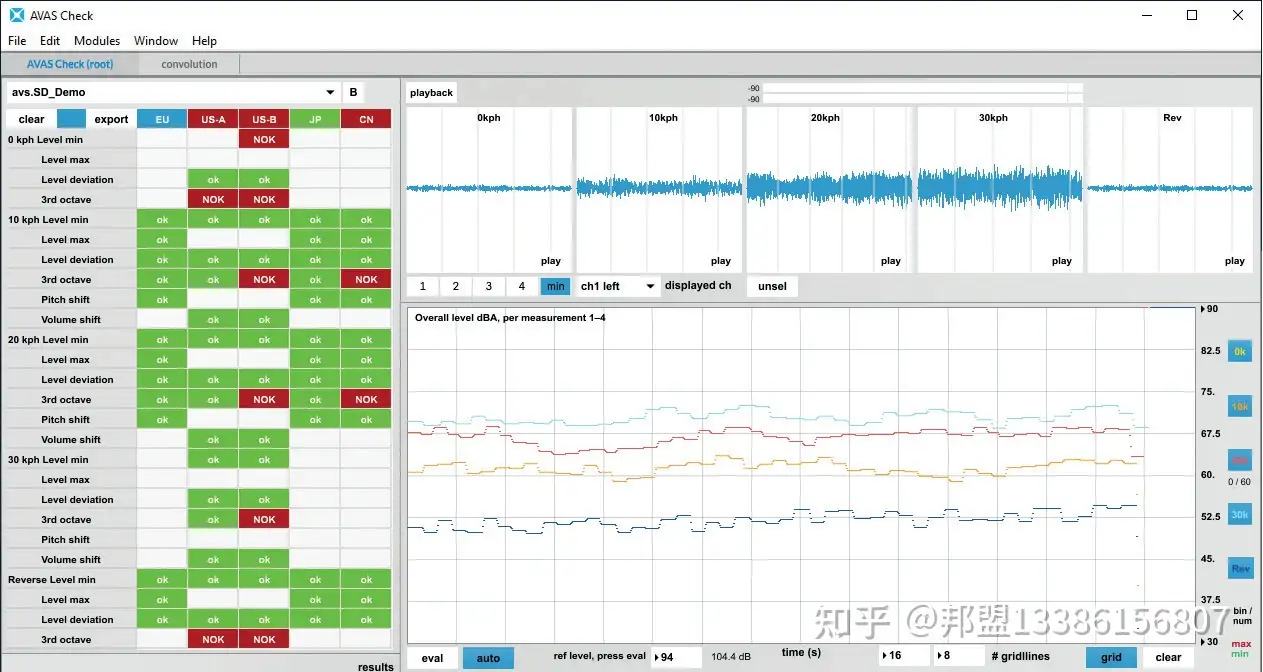
- 陪审团测试模块:通过A/B测试收集用户主观偏好,量化“品牌声学指数”。
- Simcenter 3D:
- 混合建模:低频用FEM(精度高),高频用射线追踪(速度快),覆盖全频段(图2)。
- AML技术:仅需建模车辆表面空气层,计算效率提升5倍。
3.2 硬件在环测试:从CAN总线到声场麦克风阵列
- 原型车集成:通过CAN总线实时获取车速、扭矩,动态调整声模参数。
- 环境噪声补偿:在风洞中模拟城市背景噪声(如60 dB),验证AVAS声音可辨性。
第四部分 品牌声学:从合规到差异化的战略跃迁
4.1 用户心智争夺战:声音如何成为品牌“第二Logo”?
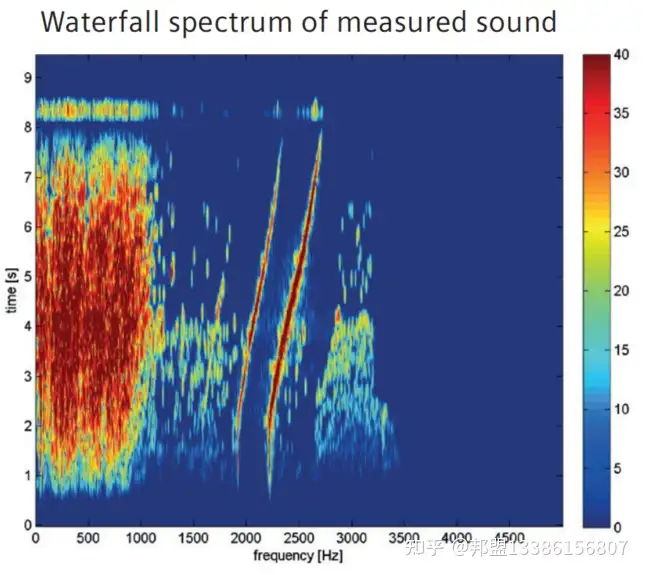
- 案例:日产Leaf的“星际迷航音”:
通过高频谐波(2,000-3,500 Hz)与低频脉动(600 Hz)组合,塑造科技感,同时满足法规频段要求(图7)。
- 特斯拉的“沉默争议”:
早期Model S因警示音过于机械引发用户吐槽,后续通过OTA更新引入多套“皮肤音效”。
4.2 声学营销:从功能到情感的升维
- 奔驰EQ系列的“银箭之声”:
灵感源自1930年代赛车,通过颗粒合成复刻历史引擎音,唤醒用户情感共鸣。 - 用户自定义声效:
部分车企开放声效商店,允许用户下载“科幻/经典”音效包,增强参与感。
第五部分 未来展望:智能声景与城市声态的重构
5.1 车联网(V2X)协同:动态声学生态
- 群体智能:多车AVAS协同,避免声波干扰,形成“安全声场走廊”。
- 与交通信号联动:红灯时增强警示音,绿灯时降低音量。
5.2 人工智能与生成式声学
- AI声学引擎:
通过GAN(生成对抗网络)自动设计合规且个性化的警示音,替代传统合成器。 - 情绪感知:
根据行人姿态(如低头看手机)调整音调紧迫性。
5.3 城市声景的“绿化”挑战
- 噪声污染悖论:
AVAS可能加剧城市声压级,需通过定向技术将声能限制在必要区域。 - 政策博弈:
东京等城市已提案“AVAS音量上限”,车企需在安全与环保间寻找平衡。
结语:寂静时代的声学使命
AVAS的诞生,既是技术对安全的回应,也是人类对城市声景的重新定义。当电动车的声音从“合规义务”升华为“品牌语言”,声学工程师的角色也悄然转变——他们不仅是物理定律的解读者,更是未来城市声态的建筑师。
在这场革命中,西门子的工具链提供了一条从虚拟到现实的桥梁,但更深层的挑战在于:我们是否准备好迎接一个“主动发声”的智能交通时代?当每辆车都能“说话”,城市将如何倾听?
延伸讨论:
- 你认为未来电动车的声音应该更像传统引擎,还是彻底颠覆?
- 如果AVAS开放用户自定义,你会选择什么风格的声音?





